With so much competition in the business world, it is important to have accurate information about the contact.With all the competition out there, it is crucial to have accurate contact information for successful sales and marketing, recruitment and networking campaigns. An email scraper can assist companies automate the process of amassing direct contact email addresses from freely available online sources and arrange them into structured EXCEL spreadsheets. Rather than visiting websites and directories and manually entering information, companies can extract thousands of verified contacts in mere moments with advanced email extraction methods.
From startups seeking potential customers to recruitment agencies seeking skilled candidates or marketing teams creating outreach campaigns, an Email Scraper can significantly boost productivity and accuracy of data. Organizations can build specific contact lists from websites, business directories, social media, and public repositories to aid in business expansion and customer acquisition.
An email scraper is a certain type of data scraper or service used to locate, collect and classify e-mail addresses that are present in publicly accessible online content. This data is typically delivered in a structured format, such as CSV or Microsoft Excel spreadsheet, and can be easily accessed and imported into CRM systems for analysis.
The main purpose of an Email Scraper is to harvest direct contact email addresses without ever having to do it manually or by mistake. Besides extracting the basic data, contemporary scraping solutions can also accumulate more comprehensive business details consisting of names, addresses, phone numbers, websites, locations, and social media profiles.
Building a quality contact database manually can take weeks or even months. An Email Scraper streamlines this process by collecting valuable contact information quickly and efficiently.
Businesses that use professional Email Scraper solutions often achieve higher response rates because they can focus their efforts on verified and relevant contacts.
The process typically involves several stages to ensure data quality and accuracy.
| Step | Process | Description |
|---|---|---|
| 1 | Target Identification | Identify websites, directories, or platforms containing contact information |
| 2 | Data Extraction | Use scraping tools to collect email addresses and related information |
| 3 | Data Cleaning | Remove duplicates and invalid entries |
| 4 | Email Verification | Validate email formats and activity |
| 5 | Data Organization | Structure information into Excel spreadsheets |
| 6 | Quality Review | Perform manual and automated checks |
| 7 | Delivery | Provide final Excel or CSV database |
This systematic approach ensures the final spreadsheet contains accurate and actionable business contacts.
A professional Email Scraper can gather much more than email addresses.
| Data Field | Description |
|---|---|
| Contact Name | Individual or decision-maker name |
| Email Address | Direct contact email |
| Company Name | Business organization |
| Phone Number | Public contact number |
| Website URL | Company website |
| Job Title | Position within organization |
| Industry | Business category |
| Location | City, State, Country |
| LinkedIn Profile | Public profile URL |
| Social Media Links | Available public profiles |
This comprehensive data helps businesses create highly targeted outreach campaigns.
Many industries rely on Email Scraper services for lead generation and market research.
Software providers use contact databases to connect with decision-makers and IT professionals.
Recruiters leverage direct contact information to identify and engage potential candidates.
Agents collect property owner and business contact details for prospecting activities.
Marketing teams build targeted outreach campaigns using verified contact databases.
Online retailers identify partnership opportunities and wholesale prospects.
Consultants use business directories to connect with executives and stakeholders.
Excel spreadsheets remain one of the most popular formats for storing and managing extracted contact information.
| Benefit | Explanation |
|---|---|
| Easy Sorting | Organize data by industry, location, or company |
| Data Filtering | Quickly find specific contacts |
| CRM Integration | Import into Salesforce, HubSpot, and other systems |
| Reporting | Create dashboards and analytics |
| Data Validation | Identify duplicates and errors |
| Collaboration | Share with team members easily |
An organized spreadsheet improves accessibility and makes contact databases more useful for sales and marketing operations.

To maximize results, businesses should follow several best practices when using an Email Scraper.
Identify websites and directories that align with your target audience.
Always validate collected contacts before launching outreach campaigns.
Duplicate contacts can negatively impact campaign performance.
Contact information changes frequently, making regular updates essential.
Maintain standardized formatting for easier analysis and CRM imports.
While an Email Scraper provides significant advantages, organizations may encounter certain challenges.
| Challenge | Solution |
|---|---|
| Duplicate Emails | Automated deduplication |
| Invalid Contacts | Email verification tools |
| Large Data Volumes | Automated processing workflows |
| Inconsistent Formats | Data normalization techniques |
| Website Structure Changes | Adaptive scraping solutions |
Professional scraping services help overcome these challenges while maintaining data quality.
A professional Email Scraper service delivers higher-quality results than many free tools. Experienced data extraction specialists understand how to collect information efficiently, clean datasets, verify contacts, and organize records into usable Excel spreadsheets.
Businesses benefit from:
By outsourcing email extraction projects, organizations can focus on converting leads rather than spending valuable time gathering contact information manually.
For businesses looking for reliable and structured direct contact email addresses and Excel databases, an Email Scraper is a must-have solution. Whether you’re looking to generate leads or recruit new staff, or need to conduct market research or send out sales emails, automated email extraction can save you valuable time, boost efficiency, and provide you with valuable business intelligence.
When verified contact information is maintained in professional spreadsheet applications, businesses can carry out more targeted campaigns, boost response rates and boost business development. By investing in professional email extraction services, businesses can reap benefits such as precise data collection, efficient workflows, and ongoing value for marketing and sales teams.
An Email Scraper is a tool or service that automatically extracts publicly available email addresses and related contact information from websites and online directories.
Email scraping legality depends on local regulations, website terms of service, and how the collected data is used. Always comply with applicable privacy and marketing laws.
Yes. Professional scraping services can collect publicly available business contact email addresses from company websites, directories, and industry portals.
Most projects deliver data in Excel spreadsheets (.xlsx) or CSV files for easy import into CRM and marketing platforms.
Accuracy depends on the source and verification process. Professional services typically validate and clean data before delivery.
Yes. Data cleaning processes automatically identify and remove duplicate records.
Technology, recruitment, marketing, real estate, consulting, e-commerce, and B2B service providers commonly use email scraping services.
Professional services provide higher-quality data, better verification, customized extraction, and organized Excel reporting that supports successful outreach campaigns.
OBD-II (On-Board Diagnostics II) trouble codes are essential for the automotive industry to pinpoint and address issues within a vehicle. There is a need for exact, organized and searchable diagnostic data for mechanics, repair shops, automotive software vendors and diagnostic tool makers.
This project concentrated on developing two full-fledged XML databases from two publicly available automotive resources, extracting trouble code data from OBD-II (On Board Diagnostics). The goal was to convert unstructured Web content into structured XML datasets that could be used to incorporate it into automotive software, diagnostic platforms, mobile applications, or repair management applications.
The client required high-quality data extraction while preserving the relationships between codes, descriptions, symptoms, causes, technical notes, and other diagnostic information.
The primary goal was to scrape thousands of automotive diagnostic records and organize them into two independent XML databases.
The databases needed to:
Because automotive diagnostic information is highly technical, maintaining data integrity was one of the most important project requirements.
The project consisted of scraping information from two different automotive websites.
Engine Codes website
Coverage:
Each code page contained multiple sections including:
OBD Codes website
Coverage:
Each page included:
Unlike Database 1, this website used a different page structure, requiring separate extraction logic.
Although the websites contained similar automotive information, their layouts were significantly different.
Some of the major challenges included:
Each website organized information differently.
One website used headings and paragraphs.
The other relied on mixed HTML layouts including:
Separate scraping logic had to be developed for each source.
The scraper needed to navigate hundreds of linked pages covering thousands of OBD-II codes.
This required:
Several fields contained multiple values.
For example:
Possible Causes
Instead of storing these as one large paragraph, every item had to become an individual XML element.
Example:
<PossibleCauses>
<Cause>Loose gas cap</Cause>
<Cause>Vacuum leak</Cause>
<Cause>Damaged hose</Cause>
</PossibleCauses>This significantly improved searchability and downstream data processing.
Database 1 also required scraping images included within the diagnostic description.
The scraper needed to:
Automotive websites often contain:
The scraper removed unnecessary content while preserving technical information.Database 2 XML Fields
Each record included:
The XML hierarchy followed a similar standardized format for consistenc
Several quality checks ensured database accuracy.
These included:
Automated validation reduced manual review time considerably.
The scraping solution utilized modern data extraction techniques.
Possible technologies included:
These tools enabled efficient extraction while maintaining accuracy across thousands of pages.
The completed XML databases offered significant value for automotive businesses.
Developers could integrate structured diagnostic data directly into:
Instead of searching large text blocks, applications could search:
This improved response times and user experience.
Every diagnostic code followed the same XML schema.
This consistency simplified:
Without scraping, collecting thousands of diagnostic pages manually would require weeks of effort.
Automation reduced project completion time dramatically while improving consistency.

OBD II
The project successfully produced two complete XML databases containing structured OBD-II diagnostic information.
Key achievements included:
The resulting databases enabled faster development of diagnostic tools, simplified maintenance workflows, and provided a reliable foundation for future automotive applications.
One of the biggest advantages of this project was transforming complex automotive diagnostic information into a structured, machine-readable format. Instead of navigating through hundreds of individual web pages, users and applications could instantly access the required OBD-II trouble code information from a centralized XML database. This significantly improved data accessibility, reduced lookup time, and enabled seamless integration with automotive repair software, mobile applications, and diagnostic platforms.
The scraping solution was designed with scalability in mind. As new diagnostic codes or updated technical information became available, the scraping workflow could be rerun to refresh the database with minimal manual effort. This approach ensured that automotive businesses always had access to the latest diagnostic information while reducing maintenance costs associated with manual updates.
This project demonstrates how web scraping can transform complex automotive reference websites into organized, machine-readable datasets. By converting thousands of OBD-II diagnostic pages into standardized XML databases, the solution eliminated manual data entry, improved data quality, and created a scalable resource for developers, repair professionals, and automotive software providers.
The success of this project also established a repeatable workflow for future automotive data extraction initiatives, making it possible to expand coverage to additional manufacturers, vehicle models, and diagnostic standards with minimal changes. Structured data of this kind supports smarter repair solutions, better customer experiences, and more efficient software development across the automotive industry.
What is OBD-II trouble code database scraping, and why is it useful? OBD-II trouble code database scraping is the automated process of collecting diagnostic trouble codes, technical descriptions, symptoms, causes, repair solutions, and related information from automotive websites and converting it into structured formats such as XML, JSON, or SQL databases. This approach eliminates manual data entry, improves accuracy, and creates searchable datasets that can be integrated into automotive diagnostic software, repair management systems, mobile applications, fleet management platforms, and vehicle maintenance solutions. By organizing complex diagnostic information into a standardized database, businesses can streamline software development, enhance user experience, and provide faster, more reliable vehicle diagnostics.
OBD-II trouble code database scraping is the process of automatically extracting diagnostic trouble codes, technical descriptions, symptoms, causes, and repair information from automotive websites and converting the data into structured formats such as XML, JSON, CSV, or SQL databases.
Structured OBD-II data makes it easier for automotive software, repair shops, diagnostic tools, and mobile applications to search, analyze, and display vehicle diagnostic information accurately and efficiently.
Depending on the source, data can include:
The extracted data can be delivered in multiple formats, including:
Yes. A well-designed web scraper can automatically crawl thousands of OBD-II diagnostic pages while maintaining consistent formatting, reducing manual effort, and improving data accuracy.
Quality assurance typically includes duplicate detection, missing field validation, HTML cleanup, XML validation, list separation for symptoms and causes, and manual spot checks to ensure the extracted data is accurate and complete.
Yes. Structured datasets can be integrated into automotive diagnostic software, repair management systems, mobile apps, vehicle maintenance platforms, APIs, and other automotive applications.
Yes. If the source website contains publicly accessible diagnostic images, image URLs or downloaded image references can be included in the database, depending on the project requirements and usage permissions.
OBD-II data scraping is valuable for:
Yes. Custom web scraping solutions can be developed for different automotive websites, provided their structure and terms of use allow data extraction. The scraper can also be adapted to export data in the format required by your business or application.
Search engine optimization has evolved significantly over the past decade. Search engines now reward websites that earn trust naturally rather than relying on manipulative SEO tactics. Businesses that invest in ethical SEO practices experience sustainable growth, stronger search visibility, and higher-quality organic traffic.
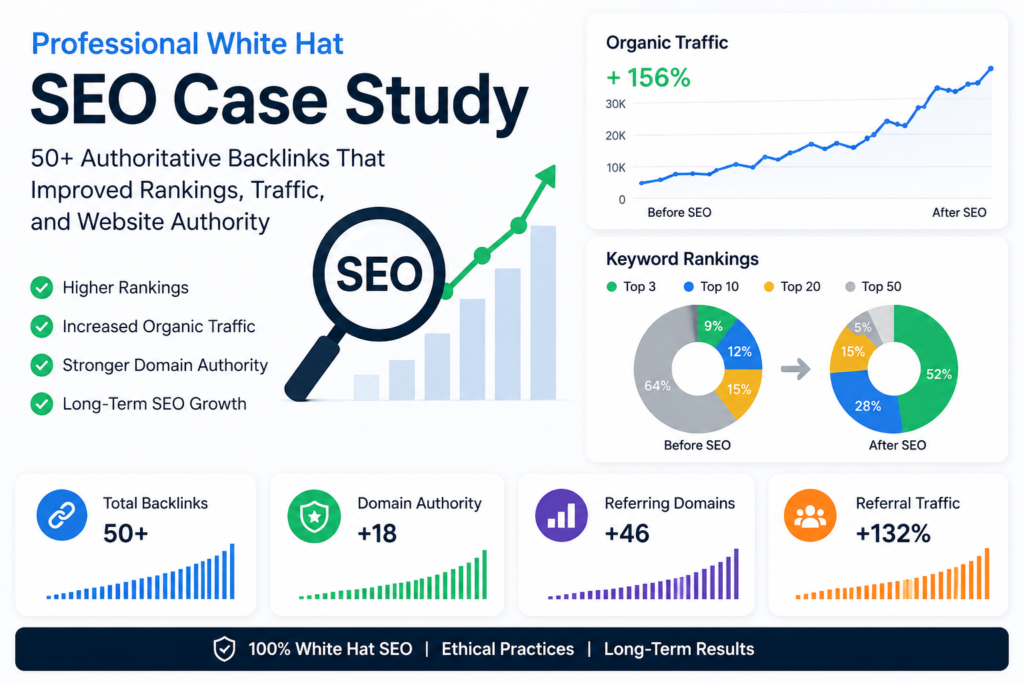
This Professional White Hat SEO demonstrates how building more than 50 authoritative backlinks helped a business improve keyword rankings, increase website authority, and generate consistent organic traffic without risking search engine penalties.
Rather than focusing on shortcuts or low-quality links, the campaign emphasized genuine relationship building, valuable content creation, and authoritative placements. The results illustrate why white hat SEO continues to outperform risky link-building strategies over the long term.
The client approached us with three primary goals:
Although the website contained quality content, its backlink profile was relatively weak compared to competitors. Most competitors had earned mentions from industry websites, blogs, business directories, and niche publications.
Before beginning the campaign, several issues limited the site’s organic growth.
Although the technical SEO foundation was solid, authority signals were insufficient for achieving higher search rankings.
The SEO campaign established measurable objectives before implementation.
| Goal | Target |
|---|---|
| High-quality backlinks | 50+ |
| Increase Domain Authority | Improve authority score |
| Organic Traffic | Consistent monthly growth |
| Keyword Rankings | Improve Top 10 rankings |
| Referral Traffic | Increase quality visitors |
| Brand Mentions | Grow industry visibility |
Each objective supported long-term organic growth instead of focusing only on short-term ranking gains.
A Professional White Hat SEO demonstrates how ethical search engine optimization techniques can deliver sustainable improvements in website rankings, organic traffic, and domain authority. Unlike shortcuts or manipulative link-building tactics, white hat SEO focuses on earning trust through valuable content, authoritative backlinks, and user-focused optimization. This approach helps businesses build a strong online presence while remaining fully compliant with search engine guidelines.
In this Professional White Hat SEO we showcase how a strategic campaign secured more than 50 high-quality backlinks from trusted and relevant websites. Through manual outreach, guest posting, digital PR, resource page link building, and content marketing, the website strengthened its backlink profile and gained greater visibility in competitive search results. Every backlink was acquired naturally, ensuring long-term SEO value rather than temporary ranking boosts.
The campaign was designed to improve keyword rankings, increase qualified organic traffic, and enhance overall website authority. Instead of focusing solely on the number of backlinks, priority was given to relevance, editorial quality, and domain credibility. As a result, the website experienced consistent growth in search engine performance, improved brand recognition, and increased referral traffic from reputable industry sources.
This Professional White Hat SEO highlights why businesses should invest in ethical SEO strategies for lasting digital success. By combining high-quality content with authoritative link-building techniques, organizations can achieve stronger rankings, attract more targeted visitors, and establish long-term credibility in their industry. The results prove that white hat SEO remains one of the most effective and reliable approaches for sustainable online growth.
The campaign avoided automated tools, private blog networks, spam directories, and paid link schemes with Professional White Hat SEO.
Instead, every backlink was earned using ethical outreach and valuable content.
Our strategy consisted of multiple components working together Professional white hat SEO.
The first step involved analyzing competing websites.
We identified:
Understanding competitor backlink profiles revealed opportunities where similar links could be earned.
High-quality content remains the foundation of white hat SEO.
We created:
This content provided genuine value, making publishers more willing to reference it.
Every outreach email was personalized.
Instead of mass emailing thousands of websites, we contacted carefully selected publishers whose audiences aligned with the client’s industry.
Outreach included:
This approach significantly improved response rates.
Guest posting remained one of the strongest white hat link-building methods.
Articles were written specifically for authoritative websites within the same niche.
Each article:
This resulted in contextual editorial backlinks that carried substantial SEO value.
Many websites maintain resource pages listing useful tools and educational content.
After identifying relevant resource pages, we contacted website owners with personalized recommendations explaining why our client’s content would benefit their readers.
Several websites accepted the submissions, producing highly relevant backlinks.
Industry publications frequently seek expert opinions.
We contributed:
This generated mentions from trusted publications while increasing brand recognition.
Broken links create poor user experiences.
We identified outdated pages linking to missing resources and suggested our client’s content as an updated replacement.
Website owners appreciated the assistance, resulting in additional editorial backlinks Professional white hat SEO.
Not every backlink provides value.
Each acquired backlink met strict quality requirements.
This ensured every backlink strengthened the website’s authority Professional white hat SEO.

Within several months, measurable improvements became visible.
Many targeted keywords moved significantly higher in search results.
Several important keywords entered Google’s first page, increasing visibility and click-through rates.
Organic traffic steadily increased as keyword rankings improved.
Visitors arrived through highly relevant search queries, leading to stronger engagement and better conversion opportunities
As more authoritative websites linked to the client, overall domain authority improved.
Higher authority also made it easier for newly published pages to rank faster.
Editorial backlinks generated direct visitors from respected industry websites.
Referral traffic produced highly engaged users because the backlinks appeared within relevant content.
Mentions from trusted publications increased credibility.
Potential customers viewed the business as an industry authority rather than simply another company competing online.
| Metric | Before Campaign | After Campaign |
|---|---|---|
| High-Quality Backlinks | Low | 50+ |
| Referring Domains | Limited | Significantly Increased |
| Domain Authority | Moderate | Higher |
| Organic Traffic | Stable | Strong Growth |
| Keyword Rankings | Page 2–5 | Many Page 1 Rankings |
| Referral Traffic | Minimal | Consistent Growth |
| Brand Visibility | Limited | Significantly Improved |
White hat SEO focuses on earning trust rather than manipulating algorithms.
Advantages include:
Unlike black hat tactics, ethical SEO continues producing results for years.
This campaign reinforced several important SEO principles.
Fifty relevant backlinks from trusted websites outperform hundreds of spammy links.
Publishers naturally reference content that provides genuine value.
Building relationships with editors and publishers creates future collaboration opportunities.
SEO is a long-term investment.
Steady outreach, content publishing, and relationship building create compounding growth over time.
Businesses looking to replicate these results should follow several best practices:
A balanced SEO strategy ensures that backlinks work alongside strong content and a technically optimized website.
Even well-intentioned SEO campaigns can fail if they rely on poor practices.
Avoid these common mistakes:
Natural growth is always more sustainable than artificial link acquisition.
This Professional White Hat SEO demonstrates that ethical link-building remains one of the most effective strategies for long-term SEO success. By earning more than 50 authoritative backlinks through manual outreach, guest posting, digital PR, resource page placements, and valuable content, the website achieved significant improvements in keyword rankings, organic traffic, referral visitors, and overall domain authority.
The campaign highlights an important lesson: sustainable SEO is built on quality, relevance, and consistency—not shortcuts. Businesses that invest in white hat SEO can strengthen their online presence, earn lasting trust from search engines, and continue attracting qualified traffic long after the campaign ends.
White hat SEO refers to ethical optimization techniques that follow search engine guidelines. It includes creating valuable content, earning natural backlinks, improving user experience, and optimizing websites without using manipulative tactics.
Authoritative backlinks signal trust and relevance to search engines, helping improve keyword rankings, domain authority, and organic traffic.
Most campaigns begin showing measurable improvements within 3 to 6 months, depending on competition, website authority, and content quality.
For many websites, 50 authoritative and relevant backlinks can significantly improve rankings. However, SEO is an ongoing process, and continued link acquisition supports long-term growth.
Yes. Guest posting on reputable, niche-relevant websites remains one of the most effective white hat link-building strategies when the content is original and valuable.
Following Google’s guidelines greatly reduces the risk of penalties because white hat SEO focuses on earning links naturally rather than manipulating rankings.
Editorial backlinks from trusted industry blogs, news websites, educational resources, and reputable business publications generally provide the strongest SEO benefits.
White hat SEO delivers sustainable rankings, protects websites from penalties, improves brand credibility, and creates long-term organic growth, whereas black hat tactics often result in short-lived gains and higher risks.
Every modern business depends on accurate information to make better decisions, reach new customers, and improve operations. Whether you are managing customer records, creating product catalogs, building lead databases, or organizing market research, handling large volumes of information manually can consume valuable time and resources.
Professional Excel Data Entry, Internet Research, Data Extraction, Image Collection, and Copy Paste services provide businesses with an efficient way to organize, process, and manage information. These services reduce manual effort, improve accuracy, and allow organizations to focus on their core business activities instead of repetitive administrative tasks.
From startups and eCommerce businesses to healthcare providers, marketing agencies, researchers, and multinational corporations, organizations rely on experienced data professionals to deliver clean, structured, and reliable datasets.In this guide, we’ll explore everything you need to know about professional data entry and research services, including their benefits, applications, workflow, and how they can help your business grow.
Excel remains one of the world’s most powerful business tools because it allows organizations to store, organize, calculate, filter, and analyze large amounts of information.
Businesses use Excel for:
Accurate Excel data entry ensures that your reports remain reliable and your business decisions are based on correct information.
| Service | Description | Business Benefit |
|---|---|---|
| Excel Data Entry | Organizing information into spreadsheets | Accurate records |
| Internet Research | Finding relevant online information | Better decision making |
| Data Extraction | Extracting structured data from websites | Saves time |
| Image Collection | Collecting product or reference images | Supports catalogs |
| Copy & Paste Work | Manual information transfer | Fast processing |
| Data Cleaning | Removing duplicates and errors | Higher accuracy |
| Data Formatting | Standardizing spreadsheet layouts | Easy reporting |
| Database Creation | Building organized databases | Improved workflow |
Professional Excel Data Entry services are essential for businesses that need accurate, organized, and up-to-date information. Whether you require Internet Research Services, Data Extraction Services, Business Data Entry, or Excel Spreadsheet Management, outsourcing these tasks helps save time, reduce manual errors, and improve productivity. From maintaining customer databases and product catalogs to organizing financial records and lead lists, experienced professionals ensure every dataset is structured, verified, and ready for business use. High-quality Data Processing Services also help companies make informed decisions based on reliable information.
In addition to spreadsheet management, businesses often rely on Image Collection Services, Copy & Paste Services, Online Data Collection, and Web Research Services to gather valuable information from multiple public sources. Whether it’s collecting product images for an eCommerce store, extracting business information from websites, converting PDF files into Excel, or building targeted lead databases, these services provide accurate and scalable solutions. By combining Data Management Solutions, Virtual Data Entry Services, and Web Data Extraction, businesses can streamline operations, improve efficiency, and focus on strategic growth instead of repetitive administrative tasks.
Excel Data Entry Services
Professional Excel data entry includes much more than typing information into spreadsheets.
Common tasks include:
A structured Excel spreadsheet makes future reporting significantly easier.
Internet research involves collecting accurate information from trusted online sources.
Businesses commonly research:
Professional researchers verify information before adding it to spreadsheets.
Data extraction involves collecting publicly available information from websites, directories, PDFs, reports, and online databases.
Typical projects include:
The extracted information is then organized into Excel or CSV files for easy use.
Many businesses require thousands of images for products, research, AI training, marketing, or catalogs.
Professional image collection includes:
Images are organized with proper filenames and folder structures for easy access.
Although simple, copy-paste projects often involve thousands of records.
Examples include:
Accuracy is critical to ensure no information is lost during the transfer.
Many industries use these services daily.
Experienced professionals reduce errors significantly.
Businesses save hundreds of hours each month.
Hiring dedicated professionals is often less expensive than maintaining in-house teams.
Structured spreadsheets improve reporting.
Projects of any size can be completed quickly.
Professional handling protects confidential business information.
Some projects involve:
Experienced professionals know how to handle these efficiently.
Companies outsource because they need:
Outsourcing allows internal teams to focus on strategic work instead of repetitive tasks.
Before hiring, look for:
Professional Excel Data Entry, Internet Research, Data Extraction, Image Collection, and Copy & Paste services play an essential role in helping businesses manage information efficiently. Whether you’re building customer databases, researching competitors, organizing product catalogs, or maintaining business records, accurate and organized data supports better decision-making and improved productivity.
By outsourcing repetitive tasks to experienced professionals, businesses can save time, reduce costs, improve accuracy, and focus on growth. Investing in reliable data management services ensures your information remains organized, accessible, and ready to support your business objectives.
Excel data entry is the process of entering, organizing, and managing information in Microsoft Excel spreadsheets accurately and efficiently.
Internet research can include market research, competitor analysis, contact information collection, business directories, product research, and industry data gathering.
Data extraction involves collecting structured information from websites, PDFs, databases, directories, and other public sources for analysis or business use.
Yes. Image collection services organize product images, brand assets, and catalog photos for online stores and marketplaces.
Yes. Large-scale copy-paste tasks can be completed more efficiently by experienced professionals while maintaining high accuracy.
Common formats include Excel (.xlsx), CSV, Google Sheets, PDF, and Word documents.
Accuracy is maintained through manual verification, quality checks, duplicate removal, and standardized formatting.
eCommerce, healthcare, finance, education, marketing, real estate, manufacturing, and research organizations commonly use these services.
Yes. Professional data service providers can manage projects ranging from a few hundred records to millions of data points.
Outsourcing reduces costs, saves time, improves accuracy, and allows internal teams to focus on higher-value business activities.
Imagine having a virtual assistant that quickly sifts through Facebook’s public pages, posts and profiles to find the data you need. That’s essentially what a Facebook data extractor does. In Australia (and everywhere), public Facebook data is a goldmine for businesses – for lead generation, competitor research, market trends and more. Even Meta itself has acknowledged that it scrapes all Australian adults’ public posts and photos for AI training, underscoring how vast and valuable this data can be.
A Facebook data extractor (also called a Facebook scraper) is a tool or service that automates the collection of publicly available Facebook information. In this post, you’ll learn how it works, why it’s useful, what to watch out for legally, and how to use it effectively.
At its core, Facebook data extraction means collecting information that people or pages have shared publicly on Facebook. This can include profile details (like names, job titles or location), page posts and comments, likes or reactions, contact info, and even public group posts. As SocLeads explains, Facebook data extraction “is the process of collecting data from Facebook profiles, pages, or groups,” including contact information, engagement metrics, post details, and more. In practice, a Facebook data extractor uses software to browse Facebook pages (often via code or a Web browser) and scrape out the visible data into a structured format (like CSV or JSON) for analysis.
Think of a Facebook scraper as an automated “copy” command. Instead of you manually clicking through profiles and copying text, the tool does it at lightning speed. It might look for every post containing certain keywords, download all entries on a public page, or gather details about a page’s followers. These tools ignore most of the website’s underlying code and focus on visible content. They typically work by sending HTTP requests to Facebook, parsing the returned HTML (or Graph API responses), and extracting the fields you specify (text, images, user names, etc.).
Using such tools saves you lots of time. Imagine manually compiling everyone who commented on a page or all listings in Facebook Marketplace it would be like counting grains of sand on a beach. With a scraper, you can gather thousands of entries in minutes. As SocLeads notes, a good Facebook data extractor “simplifies the process of gathering useful data from Facebook It helps save time and ensures more accurate data collection”.
A Facebook data extractor can turbocharge many business and research activities. Here are some key benefits:
In short, scraping turns Facebook into a structured database you can analyse. X-Byte, a web scraping service provider, emphasizes that scraping Facebook helps “businesses get valuable social media data insights that drive the business forward”. Instead of guessing, you get hard numbers: how many likes a product post got, what words people use to describe it, or even which city has the most demand for your offerings.
There are many ways to pull data from Facebook. You can code your own solution or use commercial tools. Common approaches include:
Different scraping needs call for different data. Here’s a snapshot of what businesses often extract from Facebook and why:
| Use Case | Data Extracted | Business Benefit |
| Marketplace Scraping | Product listings (titles, prices, categories, images), seller info, reviews | Conduct market research or compare prices; find best deals or product trends. |
| Ads & Ad Library | Ad text and media, targeting parameters, performance metrics (likes, comments) | Optimize your ad campaigns; spy on competitors’ ads and strategies. |
| Business Pages | Page details (likes, followers), posts, events, customer reviews | Monitor brand reputation; analyze engagement and content strategy. |
| Profile Scraping | Public profile info (name, education, connections), posts and comments | Generate targeted leads; map professional networks; find influencers. |
| Hashtags & Comments | Hashtag trends, public comments and replies (including sentiment clues) | Identify hot topics; measure public sentiment; guide content marketing. |
| Facebook Reels | Video metadata (title, description), view counts, likes/comments | Track trending videos and influencers; analyze engagement for new content ideas. |
Each row above corresponds to how X-Byte (a data scraping firm) suggests using Facebook data. As you see, the possibilities are broad. With a Facebook data extractor, you can systematically gather these data points at scale, turning Facebook into your research lab.
Before you start scraping, it’s crucial to understand the rules. In Australia, public data scraping is not outright illegal, but there are guardrails. Data published on Facebook is often user-generated content. The Australian Copyright Act generally does not protect raw facts or unoriginal data, meaning copying public post text or listings isn’t likely a copyright violation per se. In fact, Lawpath notes that “data scraping is legal but there are certain legislations and website terms and conditions [that] will be breached” if not careful. In other words, scraping itself isn’t banned, but if you scrape something that’s under copyright or if you break a site’s terms of use (like pretending to be a normal user), you could be in trouble.
Importantly, Facebook’s own policies forbid unauthorized crawling and data collection. SocLeads (a scraping service) explicitly states that its Facebook data extractor “ensures that all data extraction activities from Facebook comply with legal guidelines and Facebook’s terms of service”. On a similar note, X-Byte clarifies that it only scrapes data “that is publicly available”. This means you should never try to scrape private profiles or closed groups – doing so would violate both ethics and likely the law. X-Byte’s FAQ even notes, “No, we do not scrape data from private FB profiles or groups… We only scrape FB data that is publicly available”.
In summary: Scrape only public Facebook data, and use it in a fair and transparent way. Stay clear of any copyrighted material (like full text that a user wrote) unless you have permission, and respect privacy. Many professionals find a sensible approach is to treat scraped data much like any public market research: use it to spot trends, but not to spam or defraud individuals. As a Facebook scrap service provider notes, automated scraping is generally blocked by Facebook’s terms, but “scraping publicly available data from Facebook without violating the data protection rules can be considered legal in many areas”. Always double-check current laws and Facebook’s policies, as these can evolve.
Once you’ve decided to proceed, here are some practical tips:
By following these practices and using trusted services or libraries, you can gather Facebook data efficiently without attracting Facebook’s anti-bot measures or legal headaches.

Facebook’s public data offers a rich source of insights if you know how to tap it. A Facebook data extractor (or social media scraper) is like a magnifying glass on the vast Facebook universe, pulling out trends, contacts and content that fuel smarter decisions. In this post we saw that a well-designed extractor can save you hours of manual work, uncover marketing leads, and keep you ahead of competitors.
However, with great data comes great responsibility. Always limit your scraping to what’s public, and use that data ethically and legally. The Australian legal landscape generally permits public data scraping as long as you respect copyright and privacy rules. The safest route is to treat scraped Facebook data like any other public research material: use it to inform your strategy (market research, lead gen, content planning) but never to harass or exploit individuals.
If you’re looking for a custom Facebook data extractor or reliable web scraping services, our team is here to help. We develop scalable and secure data extraction solutions tailored to your business requirements, delivering clean, structured data in formats such as CSV, Excel, JSON, or via API integration.
Contact us today to discuss your project, request a free consultation, or receive a customized quote. Our experts will help you build a data extraction solution that aligns with your business goals and delivers meaningful results.
A Facebook data extractor is a tool or service that collects publicly available information from Facebook pages, business profiles, public posts, and other accessible content into structured formats like CSV or Excel.
Scraping publicly available information may be permissible depending on applicable laws, platform terms, and the specific use case. Businesses should always comply with relevant regulations and respect privacy requirements.
Publicly available data may include business names, page URLs, contact information (when public), follower counts, reviews, ratings, public posts, business hours, and website links.
Marketing agencies, researchers, recruiters, eCommerce businesses, sales teams, startups, and business intelligence firms commonly use Facebook data extraction.
Professional providers offer customized scraping solutions, higher accuracy, better scalability, technical support, data cleaning, scheduled scraping, and reliable delivery compared to basic scraping tools.
Businesses today depend on web data for market research, competitor monitoring, pricing analysis, lead generation, and business intelligence. However, collecting large amounts of website data consistently is not possible without proper scraping infrastructure. One of the most important components of professional web scraping is proxy rotation.
Proxy rotation plays a critical role in maintaining stable and uninterrupted data extraction. Websites actively monitor traffic patterns and often block repeated requests coming from a single IP address. Without rotating proxies, large-scale scraping projects can quickly fail due to bans, CAPTCHAs, request limitations, or temporary access restrictions.
At DataScraper, we use advanced proxy rotation systems to help clients collect accurate and reliable data from websites at scale while minimizing interruptions and improving scraping efficiency.
Modern websites are designed to detect automated traffic. If thousands of requests come from one IP address within a short period, the website may identify the activity as suspicious and restrict access. This becomes a major challenge for businesses that require continuous data collection from eCommerce platforms, search engines, directories, travel websites, marketplaces, and other online sources.
Proxy rotation helps distribute requests across multiple IP addresses, making scraping activity appear more natural. Instead of relying on one connection, requests are spread through rotating proxies from different locations and networks.
This is important because businesses today require:
Without proper proxy rotation, these scraping operations often become unstable and inconsistent.
A strong proxy rotation system directly improves the quality and reliability of web scraping projects. Businesses collecting high-volume data need scraping systems that can operate continuously without frequent blocking.
Rotating proxies help by:
When requests are distributed across multiple IP addresses, websites are less likely to detect scraping activity. This allows scraping operations to continue smoothly for longer durations.
Proxy rotation allows scraping systems to process multiple requests simultaneously using different IPs. This significantly increases scraping speed and efficiency for large datasets.
Businesses that scrape thousands or millions of pages require scalable infrastructure. Rotating proxies make it possible to handle enterprise-level data extraction projects reliably.
Some websites display different content based on geographic location. Rotating residential or regional proxies helps collect location-specific pricing, search results, advertisements, and product information.
A properly managed proxy rotation system helps reduce failed requests, connection errors, and interruptions, resulting in cleaner and more complete datasets.
Many industries depend on rotating proxies to maintain accurate and consistent data collection operations.
Online retailers and brands use proxy rotation to monitor competitor pricing, product availability, discounts, reviews, and inventory updates across marketplaces.
SEO agencies and digital marketers scrape search engine results pages to track rankings, keywords, advertisements, and competitor visibility. Proxy rotation helps avoid search engine restrictions during large-scale SERP scraping.
Businesses scraping company directories, business listings, and public contact databases use rotating proxies to collect leads efficiently without interruptions.
Travel companies monitor airfare, hotel pricing, and availability across multiple platforms using large-scale rotating proxy networks.
Researchers and analytics firms collect structured data from various public sources for trend analysis, demand forecasting, and business intelligence.
At DataScraper, we provide professional web scraping solutions supported by advanced proxy rotation infrastructure. Our systems are designed to handle high-volume scraping projects efficiently while maintaining data accuracy and reliability.
We help clients by:
Our team develops custom scraping workflows based on project size, target websites, update frequency, and business goals.
Successful web scraping is not only about extracting website data. It also depends on maintaining stable infrastructure capable of handling website restrictions and anti-bot systems. Proxy rotation is one of the most important technologies that makes modern web scraping scalable and reliable.
Businesses that rely on accurate and continuously updated data need scraping systems that can operate efficiently without interruptions. With the right proxy rotation strategy, companies can collect large volumes of data safely, consistently, and at scale.
Looking for scalable web scraping solutions with reliable proxy rotation infrastructure? DataScraper helps businesses collect accurate website data for pricing intelligence, lead generation, SEO monitoring, market research, and automation projects. Contact us today to discuss your custom web scraping requirements.
In today’s fast-moving digital economy, financial decisions are no longer made solely on intuition or delayed reports. Investors, hedge funds, financial analysts, fintech companies, and businesses increasingly rely on real-time financial data to identify opportunities, reduce risks, and improve forecasting. One of the most effective ways to collect this valuable information is through financial market data scraping.
Financial market data scraping refers to the process of extracting structured financial information from websites, online portals, stock exchanges, market dashboards, news sites, and financial platforms. This data may include stock prices, forex exchange rates, commodity prices, company fundamentals, economic indicators, market news, analyst ratings, and much more.
By using web scraping techniques, organizations can build custom datasets tailored to their investment strategy, competitor tracking, research goals, or operational needs. Instead of manually visiting dozens of websites every day, businesses can automate the process and gain instant access to clean, actionable market insights.
In this blog, we’ll explore how financial market data scraping supports better decision making, what types of financial data can be collected, its major benefits, real-world use cases, challenges, and best practices for implementation.
Financial market data scraping is the automated extraction of financial information from public or authorized online sources. It allows businesses and analysts to gather large volumes of data from multiple financial platforms and convert that information into structured formats such as Excel, CSV, JSON, APIs, or databases.
This process is useful for collecting:
For example, an investment company may scrape stock exchange websites and business news portals every hour to monitor changes in stock prices and market sentiment. This helps them make faster and more accurate decisions.
Every financial decision depends on timely, accurate, and relevant data. Whether you’re managing an investment portfolio, building a trading algorithm, analyzing a sector, or studying market risks, data is the foundation of every strategy.
Without proper market data, decision-making becomes:
Financial market scraping solves this by providing businesses with up-to-date, large-scale, and customizable financial intelligence.
Businesses can scrape many categories of financial data depending on their goals. Here are the most common ones:
This includes:
Useful for banks, trading firms, and global businesses:
Essential for manufacturers, exporters, and traders:
Very important for fintech and crypto platforms:
This includes scraping:
Businesses often collect:
Market prices can change within seconds. Financial data scraping allows traders and analysts to track live market movements and respond immediately.
For example:
Businesses and financial institutions use scraped data to identify patterns, trends, and sector opportunities. This helps in:
Risk is a major factor in financial decisions. By collecting historical and live financial data, organizations can:
Financial analysts and data scientists use scraped market data to build:
If you’re running a fintech startup, brokerage firm, or financial research business, data scraping helps you stay ahead by tracking:
| Financial Data Type | What It Includes | Who Uses It | Decision-Making Benefit |
|---|---|---|---|
| Stock Market Data | Share prices, volume, P/E ratio | Investors, Analysts | Better buy/sell decisions |
| Forex Data | Exchange rates, currency trends | Banks, Traders, Exporters | Currency risk management |
| Commodity Data | Gold, oil, silver, agriculture rates | Manufacturers, Traders | Procurement and pricing strategy |
| Cryptocurrency Data | Token prices, market cap, trends | Fintech, Crypto Analysts | Trading and portfolio diversification |
| Financial News | Headlines, analyst ratings, market updates | Research Firms, Investors | Sentiment-based decision making |
| Company Financials | Revenue, earnings, reports | Businesses, Investors | Financial health analysis |
| Economic Indicators | Inflation, GDP, interest rates | Policy Analysts, Businesses | Strategic planning and forecasting |
Financial market data scraping is useful across many sectors:
Use scraped data for portfolio analysis, stock screening, and market tracking.
Build dashboards, financial tools, and automated market products.
Track exchange rates, lending markets, and economic indicators.
Monitor commodity costs, fuel prices, and currency fluctuations that impact product pricing.
Analyze financial trends and economic conditions for risk assessment.
Create industry reports, financial insights, and market forecasts.
A hedge fund scrapes stock exchange data and financial news websites every 15 minutes to detect short-term market opportunities.
An international import-export business scrapes live forex rates to decide the best time for currency conversion.
A manufacturing company monitors oil and metal prices daily to plan procurement and budgeting.
A trading platform scrapes financial headlines and news sentiment to trigger buy/sell alerts.
A fintech startup collects company financial data and startup valuation trends to support smarter funding decisions.
Although financial scraping is powerful, it comes with a few challenges:
Financial websites often update layouts, which may break scraping scripts.
Some websites use CAPTCHA, rate limiting, or IP blocking.
Raw data may contain duplicates, missing values, or formatting problems.
Always scrape public or properly licensed data responsibly and ethically.
Collecting live financial data at scale requires strong infrastructure.
To get the best results, businesses should follow these best practices:
Make sure data is properly cleaned, validated, and structured.
Keep track of source changes to avoid data disruption.
Decide whether you need hourly, daily, weekly, or real-time updates.
Save data in databases, spreadsheets, or dashboards for easy access.
Always respect terms of service, public access rules, and compliance needs.
A professional data scraping team can build secure, scalable, and reliable data extraction systems.
Many companies prefer outsourcing financial data scraping instead of building everything in-house. Why?
Because professional scraping services provide:
At Data Scraper, businesses can get custom financial data extraction solutions tailored to their industry, goals, and reporting needs.
At Data Scraper, we help businesses extract and organize valuable financial market data from public and structured online sources. Our solutions are designed to support:
Whether you need daily market updates, historical datasets, or custom financial data feeds, our team can build a solution that saves time and improves decision-making.
In a world where financial markets move rapidly and competition is intense, access to the right information can make all the difference. Financial market data scraping gives businesses, investors, analysts, and fintech companies the power to collect, organize, and act on financial intelligence faster than ever before.
From stock prices and forex rates to market news and company reports, scraping helps turn scattered online data into meaningful business insights. With better data, companies can make smarter, faster, and more confident decisions.
If your business depends on financial information, market trends, or investment analysis, financial market data scraping can become a major advantage in your decision-making strategy.
Financial market data scraping is the process of automatically collecting financial information such as stock prices, forex rates, commodity values, and market news from online sources.
It helps businesses access real-time market intelligence, improve forecasting, reduce risk, and make faster data-driven decisions.
You can scrape stock data, forex rates, cryptocurrency prices, commodity prices, company financials, analyst reports, and financial news.
It depends on the source and how the data is collected. Publicly available data can often be scraped responsibly, but businesses should always follow legal and ethical guidelines.
Investment firms, fintech companies, banks, traders, analysts, manufacturers, consultants, and research companies can all benefit from it.
We are excited to announce the successful completion of a recent large-scale data retrieval project, demonstrating both our technical expertise and our commitment to delivering impactful results.
The task focused on extracting valuable insights from search engines for a comprehensive list of celebrity names provided in an Excel file. Leveraging our large-scale web scraping service and search engine scraping service, we enhanced the scope and depth of the dataset while ensuring efficiency, accuracy, and adaptability.
The primary objective was to enrich an existing Excel file by adding structured search engine data for approximately 11,000 celebrity names. Our team designed and executed a robust workflow that included:
One of the most significant challenges was managing search engine restrictions that limit request volumes from a single IP address. Our team addressed this with an innovative and scalable approach:
This solution not only solved the immediate task but also laid the groundwork for future large-scale scraping projects that require stability, speed, and compliance with technical barriers.
By the end of the project, the client received:
In today’s data-driven landscape, organizations need reliable access to accurate web information to make smarter decisions. Our expertise in large-scale scraping, coupled with advanced infrastructure solutions like AWS Elastic IP, allows us to deliver this value at scale.
Unlike generic scraping tools or public proxy setups, our approach emphasizes:
This project is a clear example of how we bridge technical challenges with innovative solutions. We remain committed to helping businesses and researchers access the data they need—whether it’s through custom scraping solutions, API integration, or advanced cloud-based infrastructure.
If you have similar requirements—whether it involves celebrity data, product catalogs, financial data, or research datasets—our team is ready to design a tailored solution that meets your exact needs.
The successful delivery of this project highlights not only our ability to execute complex data scraping at scale but also our proactive approach to overcoming technical barriers. By combining cutting-edge technologies, cloud infrastructure, and deep expertise, we ensure our clients receive accurate, reliable, and enriched datasets.
We thank you for trusting us as your data solutions partner and look forward to continued collaboration and success in future projects.